CRF 실습 진행했다 (2) CRFSUITE 설치, CRF 개체명 인식 실습(ESP)
코드는 여기 : https://github.com/dhaldhd/crf_ner
CRFSUITE 설치는 원래 할거 벌로 없는데
그곳의 보안규정때문에 여러가지로 번거로워졌드랬다
https://python-crfsuite.readthedocs.io/en/latest/
여기 들어가면 받을 수 있따
pip install python-crfsuite 인가 치면 걍 됨 칸단데슈
참고로 실습은 python 3.5 써서함.
초-칸-단 한 실습
먼저 스페인어 개체명인식 부터 할꺼임
왜 한국어 안하고 스페인어?
응 crfsuite 예시코드가 스페인어임 헤헤
이거부터하고 한국어로 바꿔서 해볼거임
그럼 성능이 또 곤두박질치는걸 볼 수 있을거임 한국어 ㅈ같아요💗
Sample code : practice_ner_esp.py
받아서 열어라 코드 올려두겠음 커찮
Data Format
우리가 쓸 데이터는 아래와 같읍니다
열어보면 알겠지만 저 까만사진 같은 텍스트 파일임
원래 ;랑 $옆에는 형태소분석안된 원문장이 들어가는데 스페인어버젼에선 그런거 없음 걍 비워뒀다
read_file 메서드에서 텍스트파일을 읽어와서 아래 하얀 그림처럼 리스트에 착착 넣어줌
Ex) “Melbourne(Australia), 25 may (EFE).”


자질 추출

샘플코드에 #자질 추출 표시된 부분 찾아서 따라치기를 해봅시다
빨간 점선 네모쳐둔 부분이 샘플코드에선 없을 거임
한컴 타자연습하는 마음으로 따라치기를 해봅시다
뭘치고 있는건지 설명을 대충 쓰자면
웅앵웅
word2features 에서는 하나의 형태소(argument 로 들어온 sent(문장)의 i 번째 형태소)에대한 자질들의 list를 만들어서 리턴해줌 아래 사진 처럼...

주변정보도 넣어주면 좋기 때무네
하나 앞에 있는 형태소에대한 자질, 하나 뒤에 있는 형태소에 대한 자질도 추가를 해줌
(빨간 점선 박스 2번째 거랑 3번째거)
데이터에서 자질추출
샘플코드에 #data에서추출 표시된 부분 찾아서 따라치기를 해봅시다

중간출력
샘플코드에 #중간출력 표시된 부분 찾아서 따라치기를 해봅시다
 중간실행
중간실행
python practice_ner_esp.py
하면 이제 밑에처럼 자질들이 나올겨

아 갑자기 현타오네
LSTM 쓰세요
포스팅을 마칩니다.
초 칸단 요즘은 진짜 툴들이 잘돼있어가지구 걍 불러서 돌리면됨
trainer 선언하규
문장단위로 feature들 seq랑 label seq 를 trainer에 append해줌
그다음에 hyper parameter들 정의해줌
지금 실습에서 쓰는 parameter들은 빨리 돌라고 저렇게 해둔것 특히 한국어일때는 max_iteration 훨씬 크케 해줘야 할것(한 300??? 몰라 해보세요) L1 L2 penalty도 넘 큰듯
CRF도 딥러닝이랑 비슷하게 gradient descent로 학습하기 때문에
early stopping 이니 regularization term(L1, L2) 이니 쓸수 있는거
early stopping L1 penalty L2 penalty가 궁금하면 구글신에게 물어보세요
걍 over fitting 막으려구 쓴다 정도로 생각하고 여기선 넘어감
모델을 train 하고 저어기 써진 경로에 저어런 이름으로 모델을 저장함
모델로드
응 따라쳐

tagger 불러오고 모델 불러옴
모델평가
응 따라칩니다

tagger.tag 에 한문장에 대한 피쳐들의 시퀀스 보주면 prediction 찍어줌
저어기 경로 저어기 이름으로 prediction 파일 써줌
TP는 앞전 포스팅에서 설명한 True positive이고...
pred_num은 아아아 모델이 예측한 개체명 갯수
answer_num은 실제 정답 개체명 갯수
중간실행2

여기까지 짜고 돌렸을때 이러케 나오면 잘하고 있는것
Precision, Recall, F1score
#Precision, Recall, F1score 자리에 알아서 짜쇼


CRFSUITE 설치는 원래 할거 벌로 없는데
그곳의 보안규정때문에 여러가지로 번거로워졌드랬다
https://python-crfsuite.readthedocs.io/en/latest/
여기 들어가면 받을 수 있따
pip install python-crfsuite 인가 치면 걍 됨 칸단데슈
참고로 실습은 python 3.5 써서함.
초-칸-단 한 실습
먼저 스페인어 개체명인식 부터 할꺼임
왜 한국어 안하고 스페인어?
응 crfsuite 예시코드가 스페인어임 헤헤
이거부터하고 한국어로 바꿔서 해볼거임
그럼 성능이 또 곤두박질치는걸 볼 수 있을거임 한국어 ㅈ같아요💗
Sample code : practice_ner_esp.py
받아서 열어라 코드 올려두겠음 커찮
Data Format
우리가 쓸 데이터는 아래와 같읍니다
열어보면 알겠지만 저 까만사진 같은 텍스트 파일임
원래 ;랑 $옆에는 형태소분석안된 원문장이 들어가는데 스페인어버젼에선 그런거 없음 걍 비워뒀다
read_file 메서드에서 텍스트파일을 읽어와서 아래 하얀 그림처럼 리스트에 착착 넣어줌
Ex) “Melbourne(Australia), 25 may (EFE).”

샘플코드에 #자질 추출 표시된 부분 찾아서 따라치기를 해봅시다
빨간 점선 네모쳐둔 부분이 샘플코드에선 없을 거임
한컴 타자연습하는 마음으로 따라치기를 해봅시다
뭘치고 있는건지 설명을 대충 쓰자면
웅앵웅
word2features 에서는 하나의 형태소(argument 로 들어온 sent(문장)의 i 번째 형태소)에대한 자질들의 list를 만들어서 리턴해줌 아래 사진 처럼...

- bias 일단 하나 모든 형태소에대해 동일하게 들어가주규
- word.lower : 알파벳들을 전부 소문자로 바꿔줌
- word[-숫자:] : word의 뒤에서 부터 몇글자
- word.issuper : 전부 대문자면 true
- word.istitle : 맨 앞 알파벳이 대문자면 true
- word.isdigit : 숫자면 true
- postag : 응 POS 태그 아 POS 태그가 뭔지 설명해야되나 한국어면 일반명사/고유명사/조사/... 이런거 영어면 동사/명사/ 머시기 그런거 있잖오 그거 언어마다 학자마다 다르게 정의할 수 있음 보통 NNP(고유명사) NNG(일반명사) 이렇게 알파벳 대문자로 씀... 대문자들의 앞쪽 글자가 보통 더 큰 분류임 NN(명사) 그래서 postag[:2] (앞에서 부터 두글자)도 따로 한번 더 피쳐로 쓴거임
주변정보도 넣어주면 좋기 때무네
하나 앞에 있는 형태소에대한 자질, 하나 뒤에 있는 형태소에 대한 자질도 추가를 해줌
(빨간 점선 박스 2번째 거랑 3번째거)
데이터에서 자질추출
샘플코드에 #data에서추출 표시된 부분 찾아서 따라치기를 해봅시다

중간출력
샘플코드에 #중간출력 표시된 부분 찾아서 따라치기를 해봅시다
python practice_ner_esp.py
하면 이제 밑에처럼 자질들이 나올겨

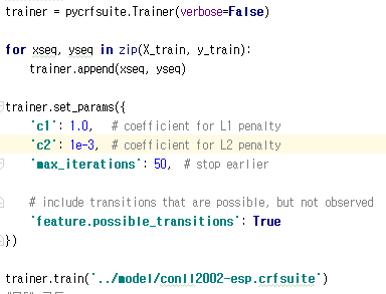
모델학습
샘플코드에 #모델학습 표시된 부분 찾아서 따라치기를 해봅시다

trainer 선언하규
문장단위로 feature들 seq랑 label seq 를 trainer에 append해줌
그다음에 hyper parameter들 정의해줌
지금 실습에서 쓰는 parameter들은 빨리 돌라고 저렇게 해둔것 특히 한국어일때는 max_iteration 훨씬 크케 해줘야 할것(한 300??? 몰라 해보세요) L1 L2 penalty도 넘 큰듯
CRF도 딥러닝이랑 비슷하게 gradient descent로 학습하기 때문에
early stopping 이니 regularization term(L1, L2) 이니 쓸수 있는거
early stopping L1 penalty L2 penalty가 궁금하면 구글신에게 물어보세요
걍 over fitting 막으려구 쓴다 정도로 생각하고 여기선 넘어감
모델을 train 하고 저어기 써진 경로에 저어런 이름으로 모델을 저장함
모델로드
응 따라쳐

tagger 불러오고 모델 불러옴
모델평가
응 따라칩니다

tagger.tag 에 한문장에 대한 피쳐들의 시퀀스 보주면 prediction 찍어줌
저어기 경로 저어기 이름으로 prediction 파일 써줌
TP는 앞전 포스팅에서 설명한 True positive이고...
pred_num은 아아아 모델이 예측한 개체명 갯수
answer_num은 실제 정답 개체명 갯수
중간실행2

여기까지 짜고 돌렸을때 이러케 나오면 잘하고 있는것
Precision, Recall, F1score
#Precision, Recall, F1score 자리에 알아서 짜쇼
앞전 포스팅에 있는 표랑 식 보고 짜보셈 쉬움
이라고 하려고 했지만 실습 시간이 부족할 것 같아서 걍 정답코드 띄웠음 이러하다

실행

스페인어 부분 끄읏
댓글
댓글 쓰기